
GPU as a Service: Break Even Analysis of GPU Clouds
What are investors underwriting when investing billions into CoreWeave & Lambda Labs?

GPU Clouds
GPU’s are all the craze these days and specialized GPU vendors have shifted from cryptocurrency mining use cases pre 2020 to monetizing the next wave of technology: Generative AI. The largest vendors in these space from a revenue perspective today outside of the three main hyperscalers are CoreWeave (>$2b projected revenue in 2024) & Lamba Labs (>$600m projected revenue in 2024). These businesses have acquired GPU’s from vendors like NVDA at a time where supply is scarce & essentially make money by renting GPU capacity to customers. We won’t get into why these businesses will exist over a longer period of time when customers can choose GPU Cloud solutions from Microsoft, AWS, Google, but the lack of supply in the market has allowed these businesses to increase relevance in the AI market.
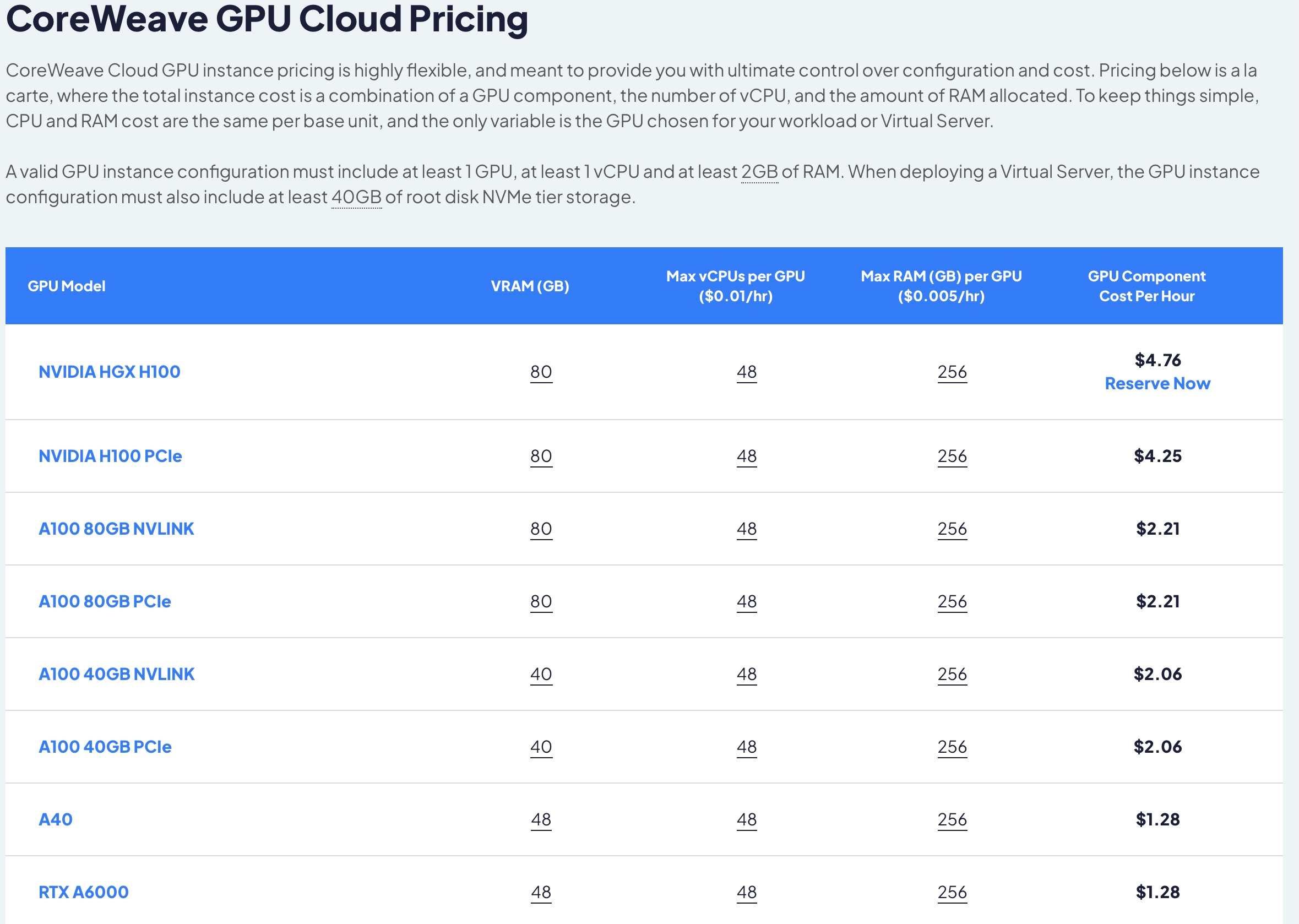
Source: CoreWeave Pricing Page
CoreWeave has raised a total of $12b in funding and Lambda Labs has raised close to $1b. Coreweave is projected to have $2.3b revenue in 2024 & a committed backlog of $7b through 2026. CoreWeave’s latest funding was primarily done via debt (not common), but is backed by customer commitments to CoreWeave. CoreWeave is not only spending on GPU’s but also has started spending on expanding DC presence in existing DC’s but also now building their own DC’s ($1.6b expenditure in building their own DC Plano, Texas DC).
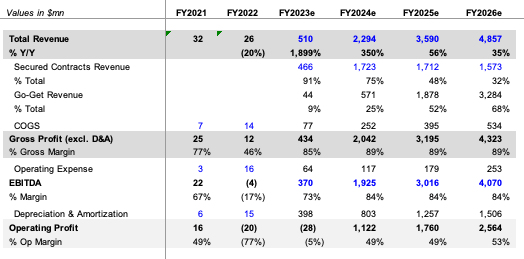
Source:
Inference vs Training Debate
Inference is the process of using a trained model to make predictions or decisions (or simply put when AI goes into production on an already built model), while Training is the phase where the model learns from data (or simply said model building).
In theory, Inference time to breakeven is faster & margins are better because it requires significantly less computational resources and energy compared to Training, which involves numerous iterations and adjustments of model parameters. This lower resource demand translates to quicker processing times and reduced costs. Additionally, Inference can in theory utilize cheaper less powerful chips like NVDA A100 chips that go for $10k, instead of NVDA H100 chips that go for $30k.
On the revenue side, Inference typically scales with usage, providing a steady stream of revenue (as long as underlying app/use case usage continues), whereas Training is often a one-time or infrequent expense customers will pay these GPU Clouds for. One of the promises investors are betting on when underwriting investments in GPU Clouds is that inferencing margins are higher than training margins, meaning as use cases shift more to inferencing, these GPU Clouds will see higher margin leverage.
How Will These Businesses Scale?
GPU Clouds need as much capital as possible to 1) build up a treasure chest of GPU’s to be able to offer scaling capacity & 2) expand the datacenters/regions that they operate in.
A simple breakeven analysis on the GPU chips cost side, is helpful to understand the math investors are doing when underwriting investments in GPU Clouds like CoreWeave & Lamda Labs. Below we’ll dive into how to determine the break-even point for renting out high-end GPUs like NVDA’s H100 PCle. The analysis & math below is simplified for the sake of illustration, but can help investors understand when businesses like CoreWeave will breakeven & scale to profitability, after supporting the heavy upfront costs needed to build out these GPU Cloud businesses.
*Note that the math presented here only takes into account the upfront costs of the GPU, and does not take into account maintenance costs, energy/power costs, server costs, etc, all of which extend the breakeven point. This example also does not make a distinction between inference or training workloads.*
GPU Breakeven Illustration
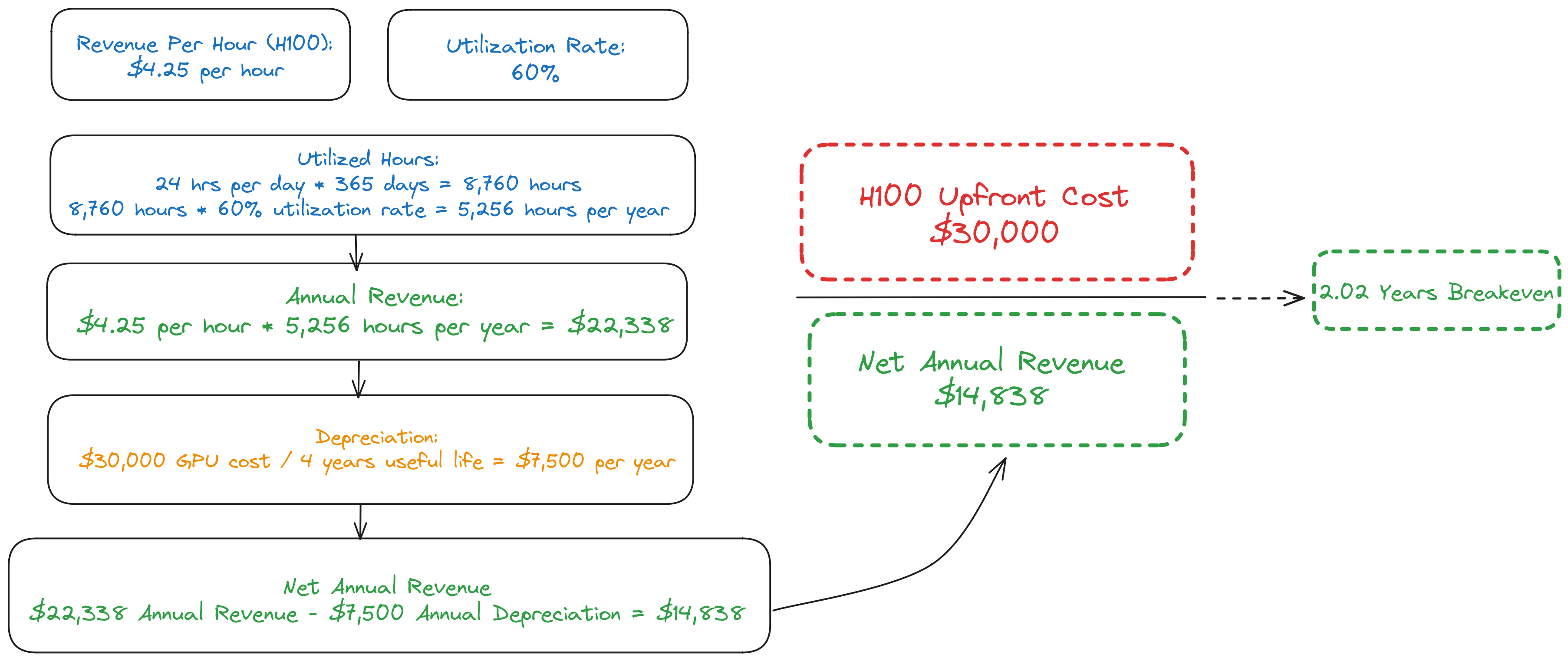
Initial Cost: A high-end H100 PCle card costs around $30,000-$40,000. CoreWeave has committed to large purchases from Nvidia & has a very good relationship with the company, so it would be fair to assume that they are on the lower end of that range. Let our starting point for this analysis use $30,000 for upfront cost.
Revenue Per Hour: CoreWeave charges customers by the hour for renting their GPU’s. On a 2 year contract list price is $4.25 an hour, but for A100’s the cost drops to $2.25. For the sake of the illustration we are not assuming any volume discounts at scale (something that their largest customer MSFT is probably getting).
Utilization Rate: The utilization rate is the percentage of time the GPU is rented out. A 60% utilization rate means the GPU is rented 60% of the time. In this example a 60% utilization rate (vs 80%+ for CPU’s) is a closer to reality for GPU’s given differing idle times o depending on the workload.
Calculating Utilized Hours: Calculate the total hours in a year: 24 hours/day * 365 days/year = 8,760 hours/year. With a 60% utilization rate, the utilized hours are 8,760 * 0.60 = 5,256 hours/year.
Annual Revenue: Multiply the hourly rental rate by the utilized hours to get annual revenue. Here: $4.25/hour * 5,256 hours/year = $22,338/year.
Depreciation: Depreciation accounts for the decrease in the GPU's value over time and matches the revenue associated with the asset. CPU’s historically have 5-7 years of useful life, but for GPU’s the useful life is lower closer to 3-4 years. This is because GPU’s are on a different pace of technological improvements, usage intensity in higher in a GPU leading to more wear, heat generation is higher causing to potential degradation, among other factors. Assuming a useful life of 4 years, the annual depreciation expense is $30,000 / 4 = $7,500/year.
Net Annual Revenue: Subtract the annual depreciation expense from the annual revenue to find the net annual revenue: $22,338 - $7,500 = $14,838/year.
Break-Even Time: Finally, calculate the break-even time by dividing the initial cost by the net annual revenue: $30,000 / $14,838 ≈ 2.02 years. This is the time it takes to cover the initial GPU chip investment.
Formulas:
Breakeven in Years = Initial Cost / Net Annual Revenue
Net Annual Revenue = (Hours in a Year x Utilization Rate x Revenue Per Hour) - (Upfront Cost / Useful Life of GPU)