


Evolution of Databases in the World of AI Apps
Why Elastic is seeing impact sooner than others, why Generative Feedback loops & Autonomous AI agents change the game, & what happens to vendors like MongoDB in a world full of Gen AI Applications

💭 Sparked by a growing narrative that MDB 0.00%↑ is not an AI winner after its last 2 quarters & an insightful conversation with
, I decided to go down the rabbit hole of digging deeper into what happens to the Database landscape in the world of AI.🔑 The thread below aims to explain the difference between OLTP databases & Enterprise Search, Vector Search, RAG, the different AI use cases/how they interact with databases, & ultimately how this impacts public software vendors in the infra space (special focus on ESTC 0.00%↑ & MDB 0.00%↑ ).
1) What is a Transactional Database (OLTP):
Traditional OLTP databases ensure data consistency and are crucial for applications that require reliable transaction processing (for example, financial transactions & ecommerce inventory management). They also handle real-time data updates and ensure that applications can process transactions quickly and accurately.
2) Enterprise Search (ESTC) vs. Transactional Databases (MDB):
Enterprise Search vendors like ESTC, excel at indexing & searching text-based data using keywords. The use cases here tend to be better for search (obviously) & analytics. ESTC is not used as a database, but its roots in Keyword Enterprise Search position it well for the adjacency of Vector Search & Hybrid Search (Keyword + Vector Search). *Historically ElasticSearch has struggled when used as a true operational database due to 1) Storage requirements given indexing methodology 2) Write loads tend to struggle in use cases with frequent updates 3) Duration of data & broader ACID transaction compliance.
Transactional Database vendors like MDB focus on storing and managing large volumes of transactional data. MDB also offers Keyword Search & rolled out Vector Search (albeit late vs competitors). Historically MDB Keyword Search has not been as performant as ESTC in use case utilizing large data sets or complex search queries & has less comprehensive Search features to ESTC.
The key here is that both are crucial but serve different purposes: search efficiency vs. data integrity and transactional consistency.
3) What is a Vector Database (or what is Vector Search):
A vector database stores data as high-dimensional vectors rather than traditional rows and columns. These vectors represent items in a way that captures their semantic meaning, making it possible to find similar items based on proximity in vector space.

Real-World Example:
Imagine you have an online store with thousands of products. Each product can be converted into a vector that captures its attributes, like color, size, and category. When a customer views a product, the vector database can quickly find and recommend similar products by calculating the nearest vectors. This enables highly accurate and personalized recommendations.
In essence, a vector database helps in efficiently retrieving similar items, which is particularly useful in applications like recommendation systems & image recognition.
4) Different Vendor Approaches in Vector Databases:
ESTC added vector search capabilities in their 8.0 release in February of 2022, their angle being focusing on their incumbency in analytics use cases & integrating with their Keyword Search. Many use cases are better suited for Hybrid Search which includes using both traditional Keyword Search & Vector Search. It’s interesting to see Pinecone, who initially was the hot startup that preached Vector Search was the only way, roll out Keyword Search capabilities in October of 2022.
MDB was a bit late to Vector Search with GA of their product only December 2023 (1.5 years after ESTC). MDB’s pitch here is the ability to use the same platform across Transactional Databases, Keyword Search, Vector Search. MDB’s advantage is it’s reach (45k+ customers vs ESTC’s 19k+ customers) and the supporting ecosystem/stack around it, in addition to integration/proximity to transactional DB (not really an advantage in some use cases today). MDB’s disadvantage here relative to ESTC is that they are not known for search despite having a competent product in that area & their focus has been on taking legacy relational transactional workloads.
5) The next step in Vector Search: Retrieval-Augmented Generation (RAG):
RAG combines the strengths of Vector Search and generative AI models to provide more accurate and contextually relevant responses. Here's how it works: 1) A user submits a query 2) the system converts the query into a vector and retrieves relevant documents or data from the vector database based on similarity 3) the retrieved documents are fed into a generative AI model (LLM), which generates a coherent and contextually enriched response using the provided data.
6) What are Multimodal Models and why are they important?
Multimodal models integrate multiple data types (text, images, audio) for comprehensive understanding and generation. It is crucial for vector databases to support multimodal data to enable more complex and nuanced AI applications. PostGres is a dominant open source vendor in the database market (scored #1 as most used Vector DB in recent Retool AI survey) but on it’s own it does NOT seem to include native support for multi-modality in it’s Vector Search. This limits the use cases it can be applied or used to without using an extension or integration to other solutions.
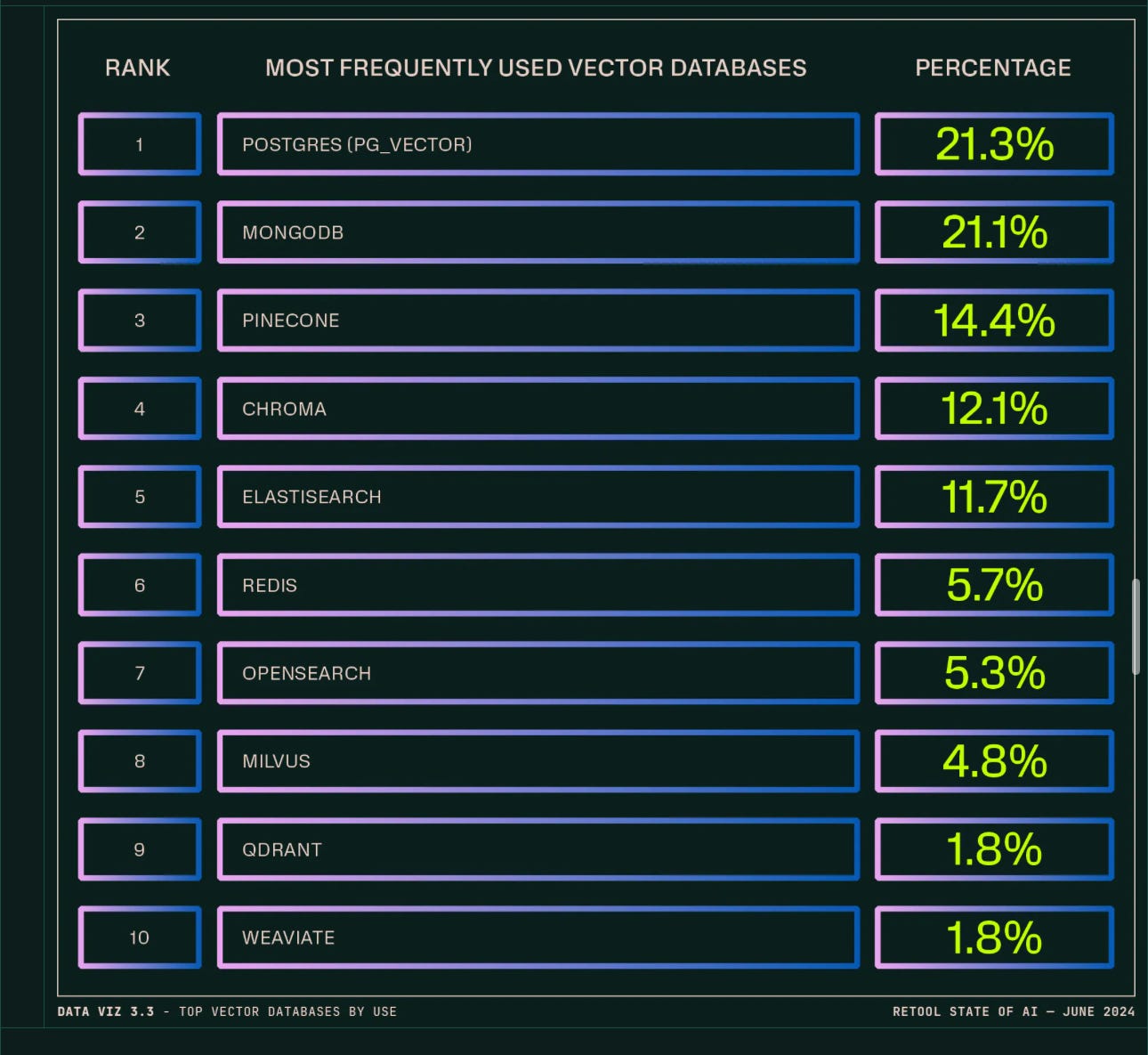
Source: Retool State of AI Survey
7) Evolution of AI Use Cases & AI Applications
Simple AI Use Cases:
Similarity Search has been one of the first and most prominent use cases of using GenAI. When a query is made, the database quickly retrieves items that are close in vector space to the query vector. This is especially useful in applications like recommendation engines & image recognition where finding similar items is crucial. These use cases have been in POC since last year, and are starting to move into production later this year.
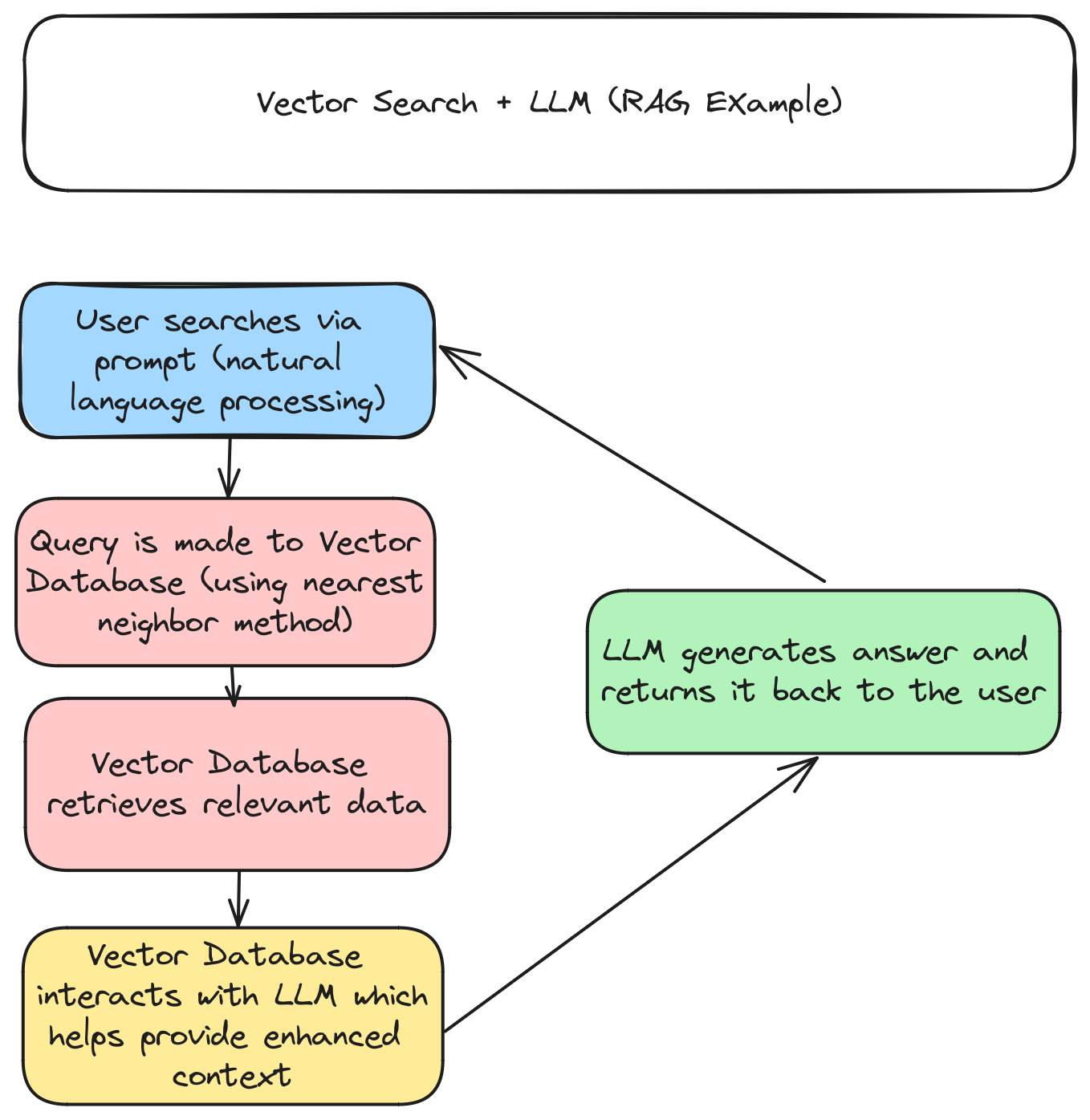
Complex AI Use Cases:
Enter Generative Feedback Loop! In a Generative Feedback Loop, the database is not only used for Retrieval of data (main use case in Similarity Search). But it also provides Storage of Generated Data. The database in this case stores new data generated by the AI model if deemed valuable for future queries. This in my view changes the relationship that the AI Application has with a database as it then has to store data back in. A key example for Generative Feedback Loop is an Autonomous Agent.
8) Relationship of the Database and AI Autonomous Agents
An AI autonomous agent and a database work together to perform complex tasks efficiently. The relationship between a database and an AI Agent at first seems similar to other use cases, where the database holds all necessary data and the AI Agent queries the database to retrieve relevant information needed to perform its tasks.
The key difference here is the Learning and Improvement aspect of AI Agents. Instead of just containing historical data, the database has been updated with new data from user interactions and agent activities. The AI Agent then uses this new data to refine its algorithms, improving its performance over time. An example of a workflow can be seen in the chart below.

A real life example could be an E-commerce Chatbot. The customer buys a product and leaves a review for that product. The database then updates the new purchase and feedback data, and the AI Agent learns from this feedback to improve future recommendations. In this scenario, the database is not just being queried for data, but it is storing data back from the interaction, the AI Agent is learning from this, creating what is referred to as a Generative Feedback Loop.
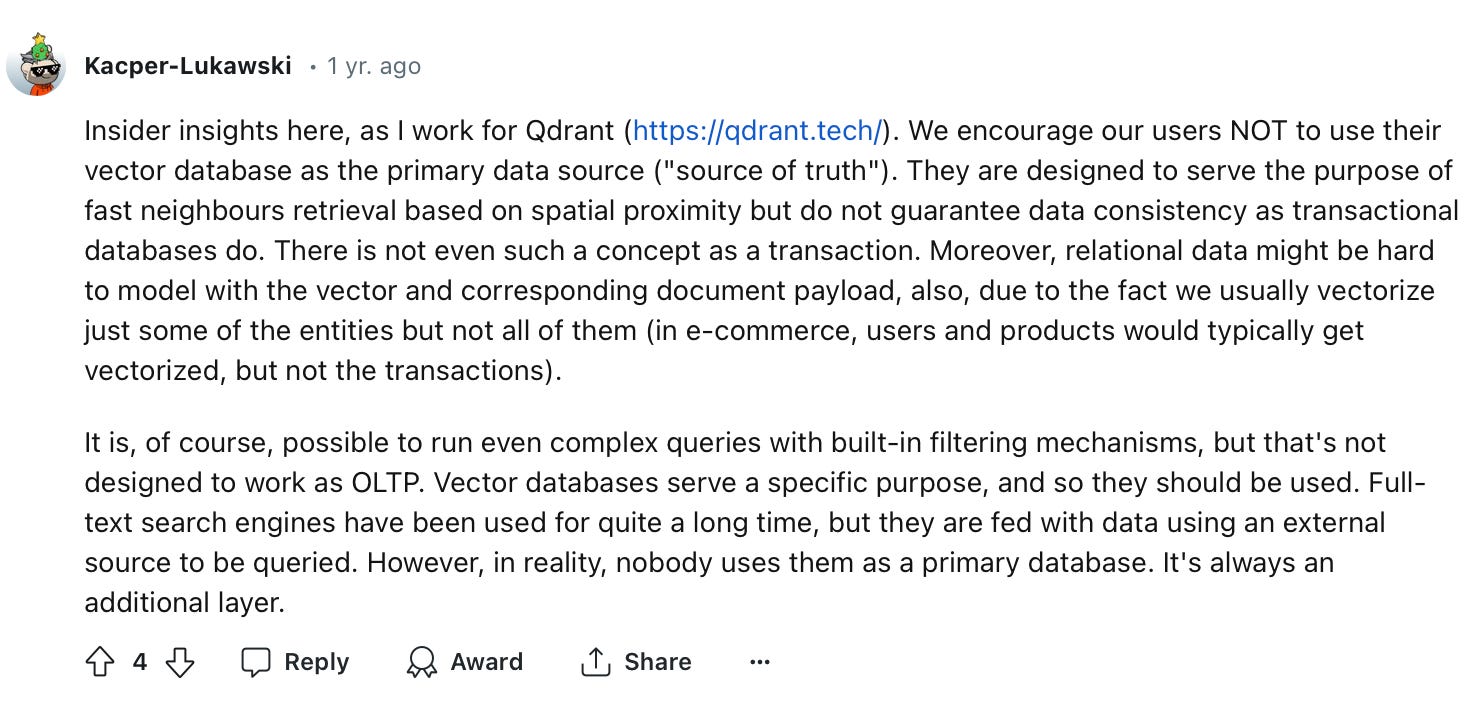
9) Limitations of Vector Databases
Vector Databases and RAG seem to be the buzz words of the day in the database space. However there are limitations with those trying to solely use Vector Databases. Some interesting threads on Reddit (here & here) from end users explain key limitations to vendors who only offer Vector Databases & lack deeper OLTP features.


10) What does this mean for MDB?
MDB Cloud Atlas Revenue has been less than stellar, with some macro impacts leading to a cut to the FY guide, when other vendors like SNOW/CFLT/DDOG with similar consumption models in the infrastructure stack have been increasing guidance. Last year investor sentiment was incredibly bullish on MDB, especially with regards to its ability to participate in the AI wave, providing tools for developers to build AI apps. However mgmt has downplayed this as more of a FY26 dynamic, which combined with the more recent guidance cut, has led to investor narratives that MDB is being crowded out by AI or losing relevance/share.
I believe that MDB could potentially see greater success in being used as the underlying data store for the Autonomous Agent type of AI uses cases, which are more complex & play into MDB’s ability to scale with fast read/write capabilities, but ultimately will take longer to come into production and ultimately into revenue.
One key difference between MDB and ESTC, is that MDB was simply late to releasing Vector Search in GA (1.5 years behind ESTC). My stand today on MDB is that it certainly can play an important role in a world full of AI applications, but needs to watch out to not lose top of funnel vs other databases like Azure Cosmos or PostGress. MDB’s biggest advantage continues to be their large customer base, product ecosystem & innovation (rolling out Stream Processing as well), creating an out of the box developer platform for developing AI tools.
It is interesting that the market is essentially placing no value on relational application migration opportunities that could come to MDB, as companies wanting to leverage AI will need to accelerate their move to the Cloud and modernize their application stack. The advancement of AI use cases from Vector Search, to RAG, to Generative Feedback loops, adds the read/write component to the equation and here MDB could benefit. ESTC could also benefit, but historically ESTC has struggled when being scaled as a traditional operational database due to limitations including indexing impact on storage & durability of data. Point here is not that ESTC is a loser in this case, more that MDB could see higher utilization in these types of use cases
*The key here is that investors seem to have forgotten that MDB didn’t win because they had the best document database, but because of the developer ecosystem, capabilities built around it, ease of use, and vendor integrations. The same should apply to Gen AI native apps, vendors aren’t going to win just because they have the best vector search capability.*
11) What does this mean for ESTC?
ESTC on the other hand, has seen some resurgence in it’s Cloud business, albeit partly due to lackluster results they had last year. As mentioned above, ESTC is primarily known for its Enterprise Search business, despite having Security/Observability products. Given their positioning and the initial use cases being tied to Search, ESTC was able to maintain relevancy. In the first days of the AI rush, investors thought ESTC to be a GenAI loser as Vector Search could commodities the traditional Keyword Search. As time passed by, investors realized that a Hybrid Search world was one that was most likely as the end state. In addition, ESTC placed Vector Search in a higher priced SKU tier, driving upgrades from customers to try out their solution. ESTC has been tied to similarity search use cases, which have been in POC’s all of last year, meaning these use cases are closer to coming to production and full consumption run rate sooner than later. In addition many of the initial use cases of GenAI apps have been driven by search/analytics, ESTC’s sweet spot. Over a longer period of time though, the question still remains on ESTC’s fit in a world where GenAI use cases move away from just being search/analytics. It will be especially interesting to see the impact of Vector Search commoditization as vendors reach feature parity, potentially eliminating ESTC’s advantage in being one of the first movers to offer Vector Search.
**For those looking to get deeper into Generative Feedback Loops, would recommend digging into Weaviate documentation (Vector DB Vendor) here & here.**